

Defining AI workflows
AI workflows typically require more than just a model call. They need pre- and post-processing steps like retrieving context, managing session history, reformatting inputs, validating outputs, or combining multiple model responses.
A flow is a special Genkit function that wraps your AI logic to provide:
- Type-safe inputs and outputs: Define schemas using Pydantic Models for static and runtime validation
- Streaming support: Stream partial responses or custom data
- Developer UI integration: Test and debug flows with visual traces
- Easy deployment: Deploy as HTTP endpoints to any platform
Flows are lightweight. They’re written like regular functions with minimal abstraction.
Defining and calling flows
Section titled “Defining and calling flows”In its simplest form, a flow just wraps a function. The following example wraps a function that makes a model generation request:
from genkit import Genkitfrom genkit.plugins.google_genai import GoogleAIfrom pydantic import BaseModel, Field
ai = Genkit( plugins=[GoogleAI()],)
class MenuSuggestionInput(BaseModel): theme: str = Field(description='Restaurant theme')
class MenuSuggestionOutput(BaseModel): menu_item: str = Field(description='Generated menu item')
@ai.flow()async def menu_suggestion_flow(input: MenuSuggestionInput) -> MenuSuggestionOutput: response = await ai.generate( prompt=f'Invent a menu item for a {input.theme} themed restaurant.', ) return MenuSuggestionOutput(menu_item=response.text)Just by wrapping your generate calls like this, you add some functionality: doing so lets you run the flow from the Genkit CLI and from the developer UI, and is a requirement for several of Genkit’s features, including deployment and observability (later sections discuss these topics).
Input and output schemas
Section titled “Input and output schemas”One of the most important advantages Genkit flows have over directly calling a model API is type safety of both inputs and outputs. When defining flows, you can define schemas for them.
You can define schemas using Pydantic models. While you can use primitive types directly as input and output parameters, it’s considered best practice to use Pydantic model-based schemas for these reasons:
- Better developer experience: Model-based schemas provide a better experience in the Developer UI by giving you labeled input fields.
- Future-proof API design: Model-based schemas allow for easy extensibility in the future. You can add new fields to your input or output schemas without breaking existing clients, which is a core principle of robust API design.
Here’s a refinement of the last example, which defines a flow that takes a string as input and outputs an object:
from pydantic import BaseModel, Fieldfrom genkit import Output
class MenuSuggestionInput(BaseModel): theme: str = Field(description='Restaurant theme')
class MenuItemSchema(BaseModel): dishname: str = Field(description='Name of the dish') description: str = Field(description='Description of the dish')
@ai.flow()async def menu_suggestion_flow(input: MenuSuggestionInput) -> MenuItemSchema: response = await ai.generate( prompt=f'Invent a menu item for a {input.theme} themed restaurant.', output=Output(schema=MenuItemSchema), ) return response.outputNote that the schema of a flow does not necessarily have to line up with the schema of the model generation calls within the flow (in fact, a flow might not even contain model calls). Here’s a variation of the example that uses the structured output to format a simple string, which the flow returns.
from pydantic import BaseModel, Fieldfrom genkit import Output
class MenuSuggestionInput(BaseModel): theme: str = Field(description='Restaurant theme')
class MenuItemSchema(BaseModel): dishname: str = Field(description='Name of the dish') description: str = Field(description='Description of the dish')
class FormattedMenuOutput(BaseModel): formatted_menu_item: str = Field(description='Formatted menu item in markdown')
@ai.flow()async def menu_suggestion_flow(input: MenuSuggestionInput) -> FormattedMenuOutput: response = await ai.generate( prompt=f'Invent a menu item for a {input.theme} themed restaurant.', output=Output(schema=MenuItemSchema), ) output: MenuItemSchema = response.outputCalling flows
Section titled “Calling flows”Once you’ve defined a flow, you can call it from your code:
response = await menu_suggestion_flow(MenuSuggestionInput(theme='bistro'))The argument to the flow must conform to the input schema.
If you defined an output schema, the flow response will conform to it. For
example, if you set the output schema to MenuItemSchema, the flow output will
contain its properties:
Streaming flows
Section titled “Streaming flows”Flows support streaming using an interface similar to the model generation streaming interface. Streaming is useful when your flow generates a large amount of output, because you can present the output to the user as it’s being generated, which improves the perceived responsiveness of your app. As a familiar example, chat-based LLM interfaces often stream their responses to the user as they are generated.
Here’s an example of a flow that supports streaming:
from pydantic import BaseModel, Fieldfrom genkit import ActionRunContext
class MenuSuggestionInput(BaseModel): theme: str = Field(description='Restaurant theme')
class MenuOutput(BaseModel): theme: str = Field(description='Restaurant theme') menu_item: str = Field(description='Generated menu item')
@ai.flow()async def menu_suggestion_flow(input: MenuSuggestionInput, ctx: ActionRunContext) -> MenuOutput: stream, response = ai.generate_stream( prompt=f'Invent a menu item for a {input.theme} themed restaurant.', )
async for chunk in stream: ctx.send_chunk(chunk.text)
return MenuOutput( theme=input.theme, menu_item=(await response).text )The second parameter to your flow definition is called “side channel”. It
provides features such as request context and the send_chunk callback.
The send_chunk callback takes a single parameter. Whenever data becomes
available within your flow, send the data to the output stream by calling
this function.
In the above example, the values streamed by the flow are directly coupled to
the values streamed by the generate_stream() call inside the flow. Although this is
often the case, it doesn’t have to be: you can output values to the stream using
the callback as often as is useful for your flow.
Calling streaming flows
Section titled “Calling streaming flows”Streaming flows are also callable, but they immediately return a response object
rather than a promise. Flow’s stream method returns the stream async iterable,
which you can iterate over the streaming output of the flow as it’s generated.
stream, response = menu_suggestion_flow.stream(MenuSuggestionInput(theme='bistro'))async for chunk in stream: print(chunk)You can also get the complete output of the flow, as you can with a
non-streaming flow. The final response is a future that you can await on.
print(await response)Note that the streaming output of a flow might not be the same type as the complete output.
Running flows from the command line
Section titled “Running flows from the command line”You can run flows from the command line using the Genkit CLI tool:
genkit flow:run menu_suggestion_flow '{"theme": "French"}'For streaming flows, you can print the streaming output to the console by adding
the -s flag:
genkit flow:run menu_suggestion_flow '{"theme": "French"}' -sRunning a flow from the command line is useful for testing a flow, or for running flows that perform tasks needed on an ad hoc basis—for example, to run a flow that ingests a document into your vector database.
Debugging flows
Section titled “Debugging flows”One of the advantages of encapsulating AI logic within a flow is that you can test and debug the flow independently from your app using the Genkit developer UI.
To start the developer UI, run the following command from your project directory:
genkit start -- uv run app.pyUpdate uv run app.py to match the way you normally run your app.
From the Run tab of developer UI, you can run any of the flows defined in your project:
After you’ve run a flow, you can inspect a trace of the flow invocation by either clicking View trace or looking on the Inspect tab.
In the trace viewer, you can see details about the execution of the entire flow, as well as details for each of the individual steps within the flow.
Flow steps
Section titled “Flow steps”Each of Genkit’s fundamental actions show up as separate steps in the trace viewer:
ai.generate()ai.embed()ai.index()ai.retrieve()
If you want to include code other than the above in your traces, you can do so
by wrapping the code in an ai.run() call. You might do this for calls to
third-party libraries that are not Genkit-aware, or for any critical section of
code.
For example, here’s a flow with two steps: the first step retrieves a menu using
some unspecified method, and the second step includes the menu in a generate()
call.
from genkit import Genkitfrom genkit.plugins.google_genai import GoogleAIfrom pydantic import BaseModel, Field
ai = Genkit( plugins=[GoogleAI()],)
class MenuQuestionInput(BaseModel): question: str = Field(description="User's question about today's menu")
class MenuQuestionOutput(BaseModel): answer: str = Field(description="Answer to the user's question")
@ai.flow()async def menu_question_flow(input: MenuQuestionInput) -> MenuQuestionOutput: async def retrieve_daily_menu() -> str: # Retrieve today's menu. (This could be a database access or simply # fetching the menu from your website.) # # ... # return "Soup: tomato bisque\nMain: roast chicken\nDessert: panna cotta"
menu = await ai.run("retrieve-daily-menu", retrieve_daily_menu)
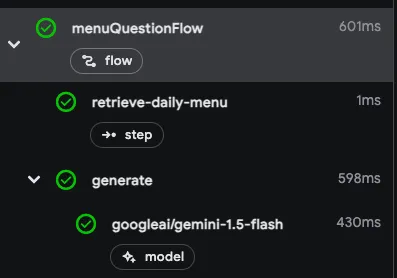
response = await ai.generate( system="Help the user answer questions about today's menu.", prompt=f"Today's menu:\n{menu}\n\nQuestion:\n{input.question}", ) return MenuQuestionOutput(answer=response.text)Because the retrieval step is wrapped in an ai.run() call, it’s included as a
step in the trace viewer:
Deploying flows
Section titled “Deploying flows”You can deploy your flows directly as web API endpoints, ready for you to call from your app clients. Deployment is discussed in detail on several other pages, but this section gives brief overviews of your deployment options.
FastAPI
Section titled “FastAPI”To deploy flows using FastAPI, create a FastAPI app and expose routes that call your flows:
import os
from fastapi import FastAPIfrom pydantic import BaseModel, Field
from genkit import Genkitfrom genkit.plugins.google_genai import GoogleAI
# Initialize Genkitai = Genkit( plugins=[GoogleAI()], model='googleai/gemini-2.5-flash',)
app = FastAPI()
class MenuSuggestionInput(BaseModel): theme: str = Field(description='Restaurant theme')
class MenuSuggestionOutput(BaseModel): menu_item: str = Field(description='Generated menu item')
@ai.flow()async def menu_suggestion_flow(input: MenuSuggestionInput) -> MenuSuggestionOutput: response = await ai.generate( prompt=f'Invent a menu item for a {input.theme} themed restaurant.', ) return MenuSuggestionOutput(menu_item=response.text)
@app.post("/menuSuggestionFlow")async def menu_suggestion_endpoint(input: MenuSuggestionInput) -> MenuSuggestionOutput: return await menu_suggestion_flow(input)
if __name__ == "__main__": import uvicorn
uvicorn.run( "main:app", host="0.0.0.0", port=int(os.environ.get("PORT", 3400)), )For production, run your app with a production ASGI server (for example, Uvicorn with Gunicorn workers):
gunicorn -k uvicorn.workers.UvicornWorker -b 0.0.0.0:3400 main:appCalling deployed flows
Section titled “Calling deployed flows”Once your flow is deployed, you can call it with a POST request:
curl -X POST "http://localhost:3400/menuSuggestionFlow" \ -H "Content-Type: application/json" -d '{"data": {"theme": "banana"}}'For streaming responses, you can add the Accept: text/event-stream header:
curl -X POST "http://localhost:3400/menuSuggestionFlow" \ -H "Content-Type: application/json" \ -H "Accept: text/event-stream" \ -d '{"data": {"theme": "banana"}}'You can also use the Genkit web client library to call flows from web applications. See Accessing flows from the client for detailed examples of using the runFlow() and streamFlow() functions.
Learn more about deployment
Section titled “Learn more about deployment”For detailed deployment instructions and platform-specific guides, see: